NetVizura already has a lot of optimizations regarding data size. For example, NetFlow Analyzer has data aggregations for defined time intervals (g1,g2, and g3 tables for examining data older than 30 days), but sometimes this is not enough. If you are storing data in TB, storing everything in fast NVMe storage doesn't make sense, mainly because of the costs. On the other side, you need to hold that data for some time based on your regulations, in-house practices, etc. (GDPR, for example). In that case, we can use Elasticsearch's built-in data tiers to fold data into performance-specific nodes. Since NetVizura 5.5, we added a remote-storage Elasticsearch database, which we will use today in this blog post.
Data tiers in elastic come in 4 flavors: hot, warm, cold, and frozen.
Usually, implementation is used in hot-warm or hot-warm-cold tiering. In our example today, we will use hot-warm-cold architecture. The hot tier will represent NVMe nodes, the fastest ones, which will hold for a few days and are commonly needed for sub-10s retrieval. Warm nodes will be on SSDs, so retrieval will be a bit slower. Lastly, cold storage will be on HDDs, where we will store the bulk of the data until deletion.
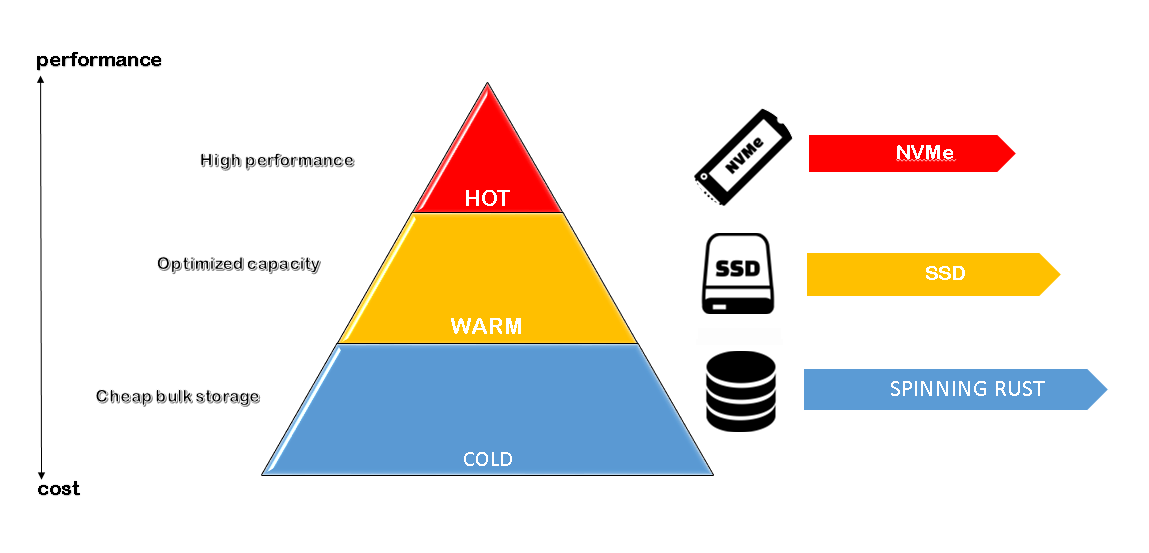
By default, Elasticsearch doesn’t know about the performance of the underlying disks, and you need to configure that on a node-per-node basis. In the elasticsearch.yml file, there is a node.roles line, where you configure these things. In our case, the options are data_hot,data_content,data_warm, and data_cold.
Once you set these options, you group Elasticsearch nodes for data tiering so that Elasticsearch knows where to store the data after some time set in ILM (Index Lifecycle Management).
By definition, the index is assigned to the data_content node, and after you apply ILM, it will go through an entire lifecycle. If needed, you can force allocation for that index by setting this specific parameter:
PUT /syslog_message_20250323/_settings
{
"index.routing.allocation.include._tier_preference": "data_hot"
}
It is essential if, in some cases, the index didn’t go through ILM.
Index Lifecycle Management
Up until now, we have only configured some per-node parameters and planned our cluster. Now, it is time to apply everything in practice.
ILM is what you need to make your indices go through hot-warm-cold architecture automatically. It can be configured either in Kibana or directly through API.
This is how that looks from the API standpoint:
{
"hot-warm-cold": {
"version": 2,
"modified_date": "2025-03-24T09:01:19.350Z",
"policy": {
"phases": {
"warm": {
"min_age": "2d",
"actions": {
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "7d",
"actions": {
"set_priority": {
"priority": 0
}
}
},
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 100
}
}
},
"delete": {
"min_age": "365d",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
},
"in_use_by": {
"indices": [
"severity_exporter_counter_20250322",
"severity_exporter_counter_20250321",
"severity_exporter_counter_20250325",
"severity_exporter_counter_20250324",
"severity_exporter_counter_20250323",
"syslog_message_20250321",
"syslog_message_20250325",
"syslog_message_20250324",
"syslog_message_20250323",
"syslog_message_20250322"
],
"data_streams": [],
"composable_templates": []
}
}
}
Configuring all this is much easier on the GUI, but let's go step by step. In our case, the name is hot-warm-cold so that it can be obvious when you look it up. There are three phases: hot, lasting 2 days; then warm, lasting 7 days; and lastly cold, which is stored for 365 days and then deleted. And this is it! No need for complex configurations and setting millions of parameters. The indices will move through our cluster after applying this to our index template.
The easiest way to apply it is to go to Kibana/Stack management/Index management/Templates and edit the template you want. In our case, that is the syslog_message template.
Edit the index settings and add the lines:
"lifecycle": {
"name": "hot-warm-cold"
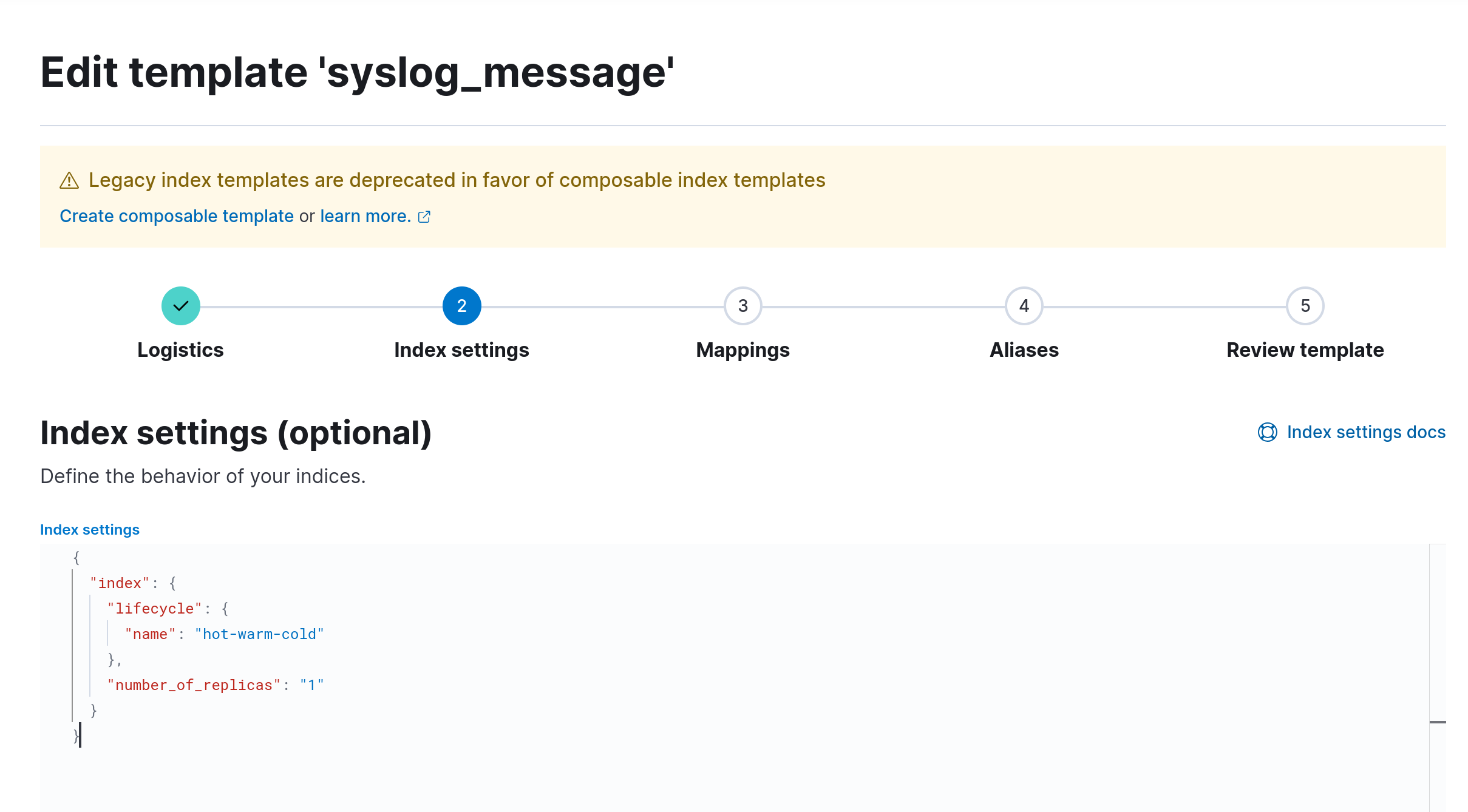
Kibana Edit template page
Look at our full index settings. There isn’t much there because it is usually not needed. The only thing there is the number of replicas for availability. How will you know if an index is picking this up? Look at the API for hot-warm-cold ILM, and you will see the indices part. They're all indices working with ILM.
Of course, when the migration occurs, you will see something like this in Elasticsearch logs:
[2025-03-25T00:03:40,884][INFO ][o.e.x.i.IndexLifecycleTransition] [elastic1-hot-warm-cold] moving index [syslog_message_20250323] from [{"phase":"hot","action":"complete","name":"complete"}] to [{"phase":"warm","action":"set_priority","name":"set_priority"}] in policy [hot-warm-cold]
And this is it! Adding more nodes is easy when you only have to set the node.roles parameter and elastic will immediately start syncing and migrating the indices.




